입출력 구조 I/O Structure
시스템은 범용 버스(시스템 버스)를 통해 데이터를 교환하는 여러 장치로 구성된 범용 컴퓨터이다.
- 인터럽트는 소량 데이터 이동에는 좋지만 NVS I/O (보조 기억 장치에서 메모리에 적재하기 위한 입출력)에는 높은 오버헤드가 발생할 수 있음.
→ 이를 위해 DMA (직접 메모리 엑세스) 를 사용한다.
DMA
- CPU 의 개입 없이 메모리로부터 자신의 버퍼 장치로 또는 버퍼로부터 메모리로 데이터 블록 전체를 전송하는 방법.
- DMA 컨트롤러를 통해 이동한다.
- “블록 전송”이 완료될 때마다 인터럽트가 발생한다.
- 여기서 블록이란, 데이터 묶음(일정 크기의 데이터를 한번에 전송하는 단위)로 이해하면 된다.
- 물론 큰 파일 요청은 여러 블록으로 나눠 처리 될 수도 있다.
컴퓨터 시스템 구조
단일 처리기 시스템 Single-Processor System
- 단순하게 코어가 하나인 단일 프로세서를 얘기한다.
- 코어 : 명령을 실행하고 로컬로 데이터를 저장하기 위한 레지스터를 포함하는 구성 요소
- 하나의 CPU 를 하나의 코어로 이해해도 무방.
- 코어 : 명령을 실행하고 로컬로 데이터를 저장하기 위한 레지스터를 포함하는 구성 요소
- 코어를 가진 CPU 는 프로세스의 명령어를 포함하는 범용 명령어 셋을 실행할 수 있음.
- 범용 명령어 셋 : 장치 컨트롤러 명령어 등..
- 운영체제는 이 처리기들이 수행할 다음 태스크에 대한 정보를 보내고 처리기들의 상태를 감시한다.
- 예 ) 디스크 컨트롤러 마이크로 프로세서는 주 CPU 로 부터 연속된 요청을 받아들여 자기 고유의 디스크 큐와 스케줄링 알고리즘을 구현 함.
- CPU 가 직접 디스크 스케줄링을 해야 하는 오버헤드를 감소 시킴.
- 처리기들은 독립적으로 자기 작업을 처리한다.
예시
사용자가 키보드에 “ㄱ” 버튼을 누른다고 가정해보자.
- 키보드에 “ㄱ” 버튼을 누르면 키보드 장치 컨트롤러가 어떤 버튼을 눌렀는지 스캔한다.
- 키보드 장치 컨트롤러는 “모니터에 ‘ㄱ’ 을 입력하라.” 는 요청을 만든다.
- 그 요청을 DMA 컨트롤러(CPU 가 사용하는 시스템 버스가 아닌)를 통해 버퍼로 옮긴 뒤, 인터럽트를 발생시킨다.
- 그 이후에는 커널(운영체제)가 요청을 처리한다.
💡 운영체제가 컴퓨터에서 일어나는 모든 요청을 처리하는 것은 아니다.
각 처리기에서 본인에게 들어온 요청을 만들고 버퍼로 보낸 뒤 인터럽트를 보내면 그 후에 운영체제가 그 요청을 처리한다.
다중 처리기 시스템 MultiProcessor System
각각 단일 코어 CPU 가 있는 두 개 이상의 프로세서 → 멀티 코어 프로세서라고 이해하면 된다.
- 프로세서는 컴퓨터 버스 및 때때로 클록, 메모리 및 주변 장치를 공유한다.
- 장점 : 프로세서 수를 늘리면 더 적은 시간에 더 많은 작업을 수행할 수 있다. → 처리량 증가
SMP symmetric multiprocessing
CPU 프로세서가 운영체제 기능 및 사용자 프로세스를 포함한 모든 작업 수행하며, 시스템 버스로 물리 메모리를 공유한다.
- 장점 : 많은 프로세스를 동시에 실행할 수 있음.
- 단점 : CPU 는 독립적이라서 하나는 유휴 상태이고 다른 하나는 과부하가 걸려 비효율적일 수 있음.
해결법 (SMP)
프로세서가 “특정 자료 구조”를 사용하여 비효율성을 피할 수 있음.
- 특정 자료구조란?
- Task Queue, Thread Pool 등을 공유 캐시(L2 캐시)에 저장.
- 예 ) 코어1이 작업 중인 상태에서 공유 캐시에 있는 작업 큐의 헤더를 변경하면, 이 정보가 L2 캐시에 저장되고 코어2는 이 정보를 활용해서 작업을 실행.
→ 프로세스 및 메모리 같은 자원을 다양한 프로세서 간에 동적으로 공유할 수 있어 프로세서 간의 부하 분산을 낮출 수 있음.
N 개의 프로세서의 속도 향상 비율은 N 배 는 아니다…?!
- 모든 프로세서가 올바르게 작동하게 유지하는 데에는 일정한 양의 오버헤드가 발생한다.
- 이 오버 헤드와 공유 자원에 대한 경합은 추가 프로세서의 예상 이득을 낮춘다.
오버헤드 예시
- 작업 분할 및 스케줄링 필요
- 작업 분배 시간이 많아지면 성능 저하.
- 자원 공유로 인한 경합
- 여러 프로세서가 공유 자원(L2 캐시, 메모리, I/O 장치 등) 에 동시 접근하려고 하면 대기 시간 발생.
- 캐시 일관성 유지
- 한 프로세서가 데이터를 변경하면 다른 프로세서의 캐시를 무효화 할 수 있음.. 데이터 동기화 비용 발생.
- 통신 비용
- 한 프로세서가 작업 결과를 생성 후, 다른 프로세서가 이를 처리해야 한다면 데이터 전송 시간 필요.
- 동기화
- 여러 프로세서가 공유 데이터에 접근한다면, 하나가 데이터를 변경하는 동안 나머지는 대기할 수 있음.
- 등등…
오버 헤드 해결법
이중 코어 설계
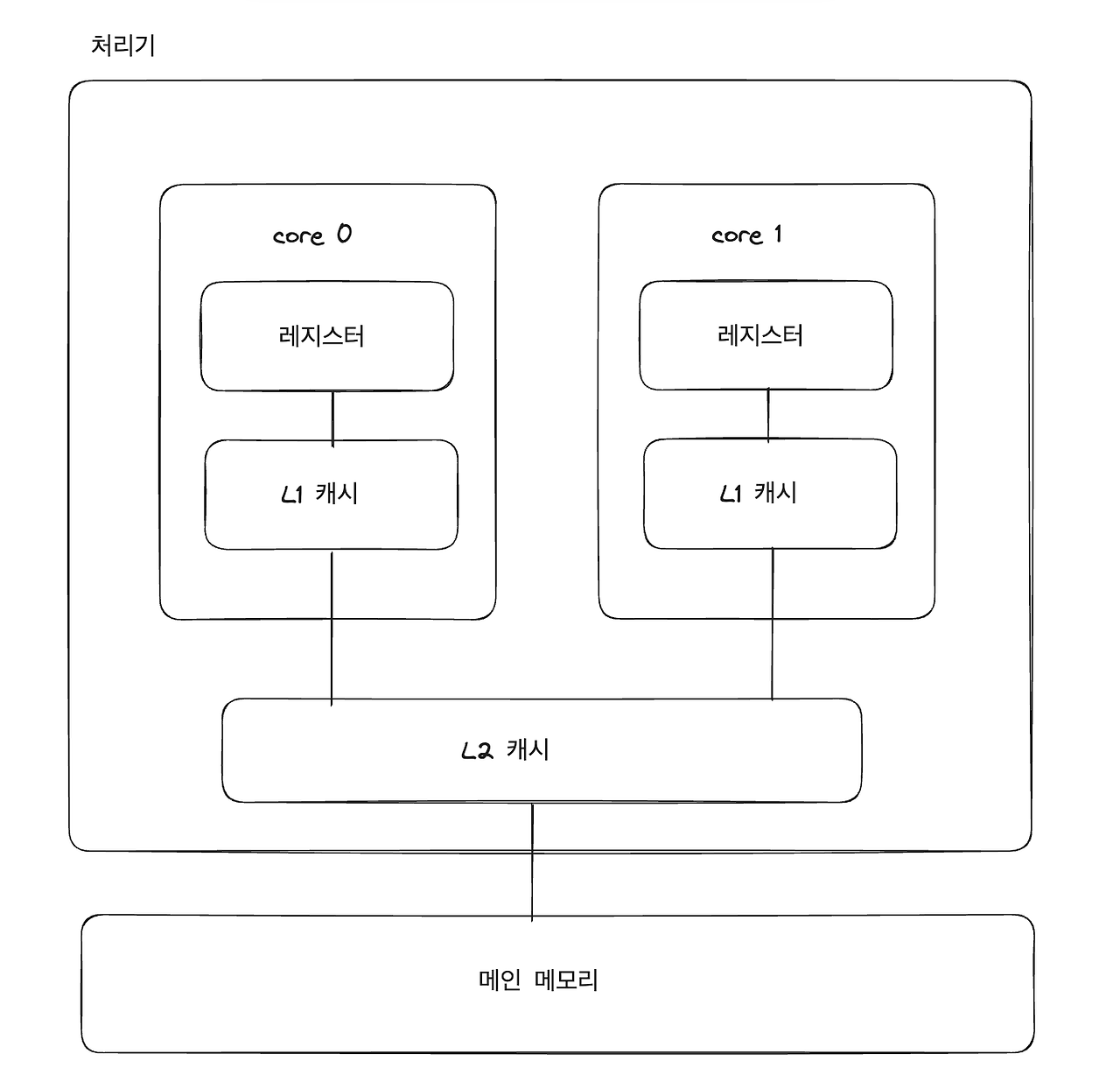
- L1 캐시는 한 코어가 가지는 로컬 캐시
- L2 캐시는 공유 캐시 → 두 코어에서 공유 됨.
- 레지스터 > L1 캐시 > L2 캐시 순으로 접근이 빠르긴 하지만, 공유 캐시를 사용하면 멀티 코어에서 효율적으로 자원(프로세스, 메모리 등)을 이용할 수 있다.
NUMA
각 CPU(또는 CPU 그룹)에 작고 빠른 로컬 버스를 이용해 액세스 되는 자체 로컬 메모리 제공.
- 모든 CPU 가 공유 시스템으로 연결되어 모든 CPU 가 하나의 물리 메모리 주소 공간 공유.
- 로컬 메모리와 원격 메모리를 나눠 관리.
- 장점
- CPU 가 로컬 메모리에 액세스 할 때 빠르다.
- 시스템 상호 연결에 대한 경합도 없음.
- (잠재적) 단점
- CPU 가 시스템 상호 연결을 통해 원격 메모리에 액세스 한다면 지연 시간이 증가하여 성능 저하가 발생할 수 있다.
- CPU 자체 로컬 메모리에 액세스 할 수 있는 만큼 빠르게 다른 CPU 의 로컬 메모리에 액세스 할 수 없어 성능 저하.
- CPU 가 시스템 상호 연결을 통해 원격 메모리에 액세스 한다면 지연 시간이 증가하여 성능 저하가 발생할 수 있다.
- 해결법
- 신중한 CPU 스케줄링 및 메모리 관리.
💡 참고로 애플 실리콘 (M1/M2 등) 에서는 UMA 방법을 채택한다고 한다. (NUMA 아님)
CPU, GPU 등이 동일한 메모리 풀을 공유하여, 메모리 접근 속도가 균일하고 로컬/원격 메모리 개념이 없음.
블레이드 서버
- 다수의 처리기, 보드(입출력 보드, 네트워킹 보드 등)를 하나의 섀시(chassis) 안에 장착. (물리적)
- chassis : 메인 보드와 비슷하다고 이해하면 됨. 하나의 책꽂이에 모든 책을 꽂아 통합.
- 각 블레이드-처리기 보드는 독립적으로 부팅되며 자신의 운영체제를 수행
- 어떤 블레이드-보드는 자체가 다중 처리기로, 컴퓨터 유형 간의 경계를 모호하게 함.
728x90
'개발공부 개발새발 > OS' 카테고리의 다른 글
| OS ) 운영체제의 작동 (0) | 2024.12.19 |
|---|---|
| OS ) 클러스터형 시스템 (0) | 2024.12.19 |
| OS ) 저장 장치 (0) | 2024.12.18 |
| OS ) 인터럽트 (0) | 2024.12.17 |
| OS ) 컴퓨터, 운영체제란 무엇인가. (2) | 2024.12.09 |
